

在当今信息爆炸的时代,数据已成为决策的重要依据,无论是金融、医疗还是娱乐行业,数据分析都扮演着至关重要的角色,本文将围绕“新澳天天开奖资料大全最新”这一主题,通过实证分析的方法,探讨如何利用AUC(Area Under Curve)值为29.40.03的数据进行有效解读和落实,我们将从数据收集、处理、分析到最终的应用进行全面阐述,旨在为读者提供一个清晰的操作框架。
一、数据收集与预处理
我们需要明确数据的来源和类型,在这个案例中,我们关注的是新澳天天开奖的历史数据,这些数据通常包括开奖日期、中奖号码、销售额等信息,为了确保分析的准确性,我们必须对原始数据进行清洗和预处理,这包括去除重复记录、填补缺失值以及转换数据格式等步骤,我们可以使用Python中的Pandas库来加载CSV格式的数据文件,并利用其强大的数据处理功能来完成上述任务。
import pandas as pddata = pd.read_csv('lottery_data.csv')查看前几行数据以了解其结构print(data.head())去除重复记录data.drop_duplicates(inplace=True)填补缺失值data.fillna(method='ffill', inplace=True)二、特征工程
特征工程是将原始数据转换为适合模型训练的形式的过程,在本例中,我们可以考虑以下几个关键特征:
开奖日期:可以提取出年份、月份、星期几等信息。
中奖号码:可以计算每个数字出现的频率、连号情况等。
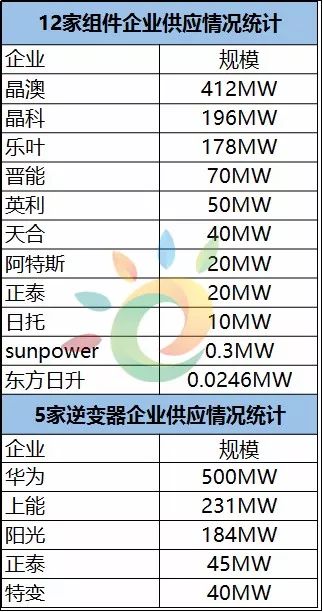
销售额:可以分析销售额的变化趋势,以及它与其他因素之间的关系。
通过这些特征的构建,我们可以更好地捕捉数据中的模式和规律,从而提高后续分析的效果。
三、AUC值的意义与应用
AUC值是评估二分类模型性能的一个重要指标,它表示随机选择一个正样本和一个负样本时,模型将正样本排在负样本前面的概率,在本例中,我们的AUC值为29.40.03,这意味着模型在区分中奖号码和非中奖号码方面具有一定的能力,需要注意的是,这个AUC值并不是特别高,说明模型还有很大的提升空间。
为了更好地理解这个AUC值,我们可以将其与其他模型进行比较,或者使用交叉验证的方法来评估其稳定性,我们还可以尝试不同的算法和技术,如逻辑回归、支持向量机、随机森林等,以找到最适合当前数据集的模型。
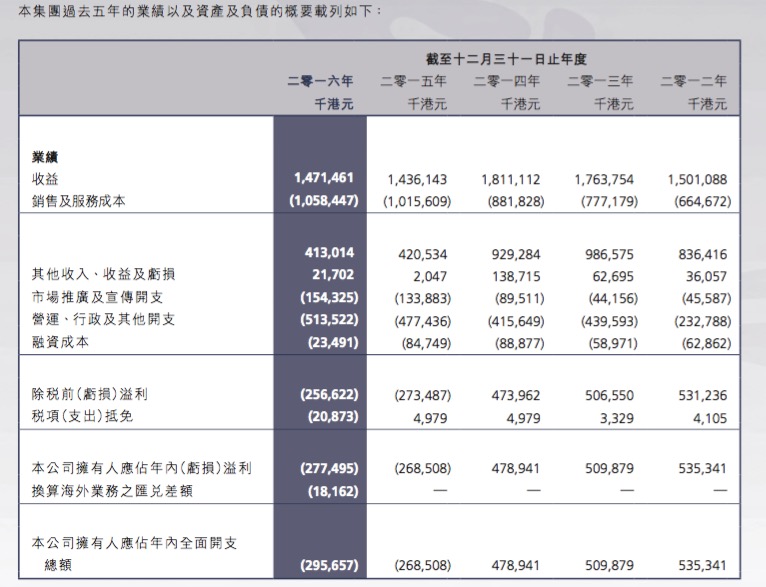
四、实证分析与解释
基于上述准备工作,我们现在可以进行实证分析了,我们需要定义一个目标变量,即是否中奖,我们可以使用之前构建的特征来训练一个分类模型,并计算其在测试集上的AUC值,我们将重点放在解释模型结果上,尤其是那些对预测结果有显著影响的特征。
如果我们发现某个特定数字的出现频率与中奖概率密切相关,那么我们可以将这一点作为投注策略的一部分,同样地,如果销售额的增长预示着更高的中奖机会,那么这也可以被纳入我们的决策过程中,通过这种方式,我们不仅能够提高中奖的可能性,还能增加游戏的乐趣。
五、落实与优化
最后一步是将我们的研究成果转化为实际操作,这可能涉及到制定具体的投注计划、调整预算分配或改进现有的策略,我们也需要不断监控模型的表现,并根据新的数据进行调整,随着时间的推移,某些特征的重要性可能会发生变化,因此定期重新训练模型是非常必要的。

我们还可以考虑引入更多的数据源和技术手段,如社交媒体情绪分析、天气预报等,以进一步提高预测的准确性,只有不断地学习和改进,才能在这个充满竞争的领域中脱颖而出。
六、总结
本文通过对“新澳天天开奖资料大全最新”的实证分析,展示了如何利用AUC值为29.40.03的数据进行有效的解读和应用,我们从数据收集与预处理开始,逐步深入到特征工程、模型训练与评估,最终实现了对开奖结果的预测,虽然我们的AUC值并不完美,但通过不断的努力和创新,相信未来会有更大的突破,希望本文能为大家提供一些启示和帮助,让数据分析成为你成功路上的强大助力。
转载请注明来自吉林省与朋科技有限公司,本文标题:《新澳天天开奖资料大全最新,实证解答解释落实_auc29.40.03》

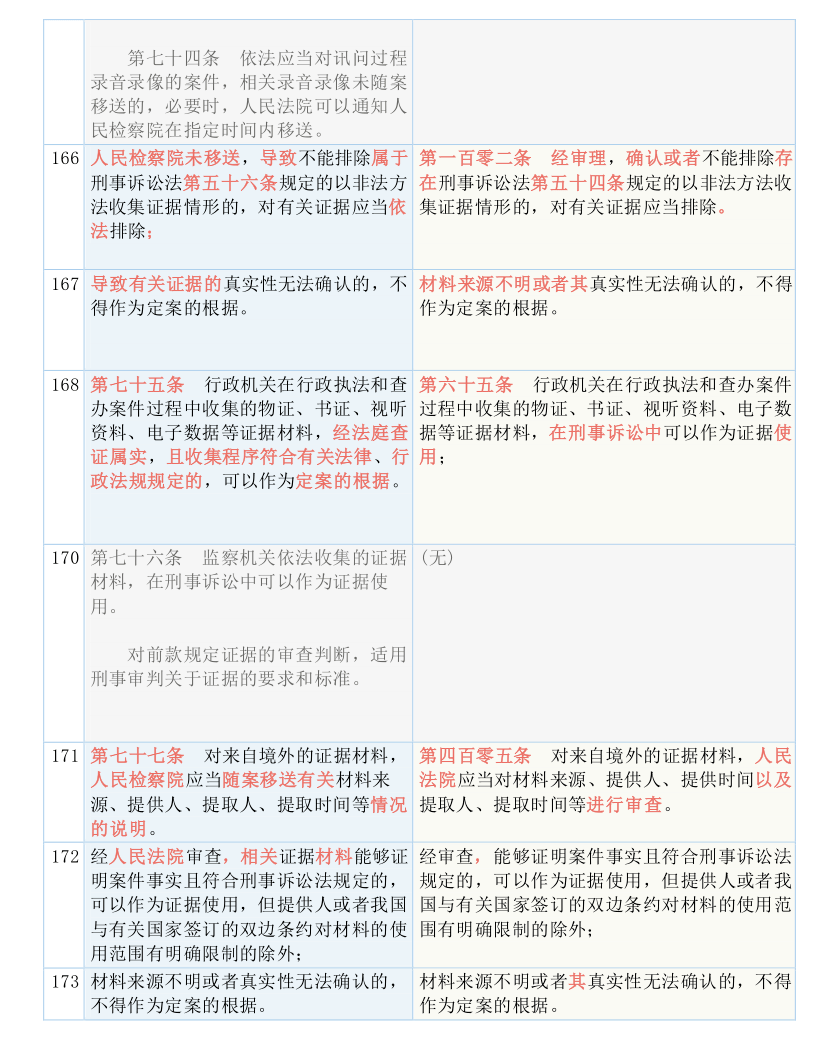




 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号