

数据分析中的“一笑一码”:追求100%准确度的综合解答与落实策略
在数据科学和分析领域,追求高准确度一直是从业者的核心目标之一。 一笑一码 在这里可以被视作一个比喻,代表着每一次编码、每一段算法的优化,都应当带来对问题理解的深入和解决方案的精准,本文将探讨如何通过综合的方法来确保数据分析的准确性,并落实到具体的操作步骤中,以期达到或接近100%的准确度。
在当今这个信息爆炸的时代,数据成为了企业决策的重要依据,数据的价值并非自动显现,它需要通过专业的分析方法和技术手段进行挖掘,在这个过程中, 一笑一码 的理念提醒我们,每一个数据处理环节都需要精心打磨,确保最终的分析结果既可靠又具有实际意义。
数据质量的重要性
要实现高准确度的分析,必须从源头抓起——即数据的质量,数据清洗是提高数据质量的关键步骤,包括处理缺失值、异常值、重复记录等问题,对于数据集中的缺失值,可以采用均值填充、中位数填充或者基于模型的预测填充等方法,而对于异常值,则需要根据业务逻辑来判断是否应该剔除或是修正。
数据的一致性和完整性也至关重要,在进行多源数据整合时,需要确保不同来源的数据格式统一,避免因格式差异导致的数据失真,对于时间序列数据,还需要注意时间戳的标准化处理,以保证时间维度上的可比性。

特征工程与选择
特征工程是提升模型性能的另一个关键环节,通过对原始数据进行转换、组合、降维等操作,可以提取出更有助于预测目标变量的特征,在这个过程中, 一笑一码 的精神体现为不断尝试不同的特征构造方法,直到找到最优解。
特征选择则是在众多候选特征中挑选出最有影响力的几个,这可以通过统计测试(如卡方检验)、基于模型的选择(如L1正则化)或者是递归特征消除法来实现,正确的特征选择不仅能够简化模型,还能提高模型的解释性和泛化能力。
模型构建与验证
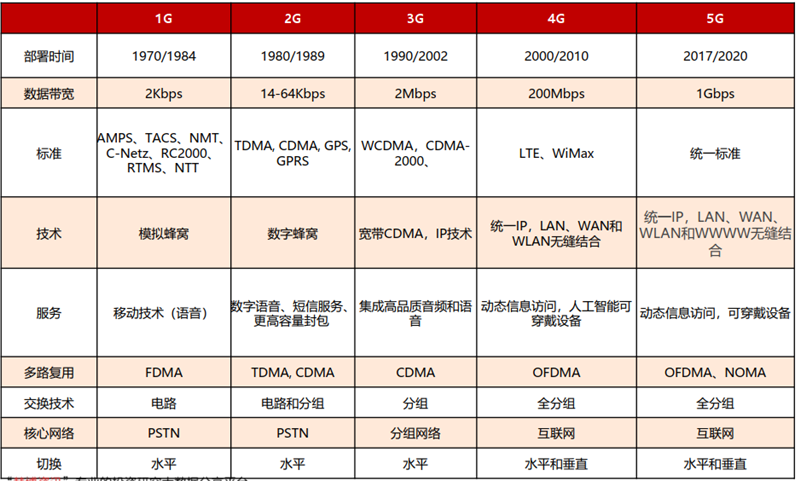
选择合适的机器学习算法对于达到高准确度同样重要,不同的问题类型(分类、回归、聚类等)可能需要不同的模型架构,对于二分类问题,逻辑回归、支持向量机和支持向量机可能是较好的选择;而对于多分类问题,则可能需要考虑随机森林、梯度提升树等集成学习方法。
模型训练完成后,必须通过交叉验证等方式对模型进行严格的评估,这不仅包括准确率这样的基本指标,还应涵盖精确率、召回率、F1分数等多个维度的性能考量,只有当所有相关指标均表现出色时,才能认为模型具备了较高的准确度。
实施与监控
即使模型在测试集上表现良好,也不能保证其在实际应用中同样有效,持续监控模型的表现并及时调整是非常必要的,这包括但不限于定期重新训练模型以适应新的数据分布,以及设置警报机制以便在模型性能下降时迅速采取行动。
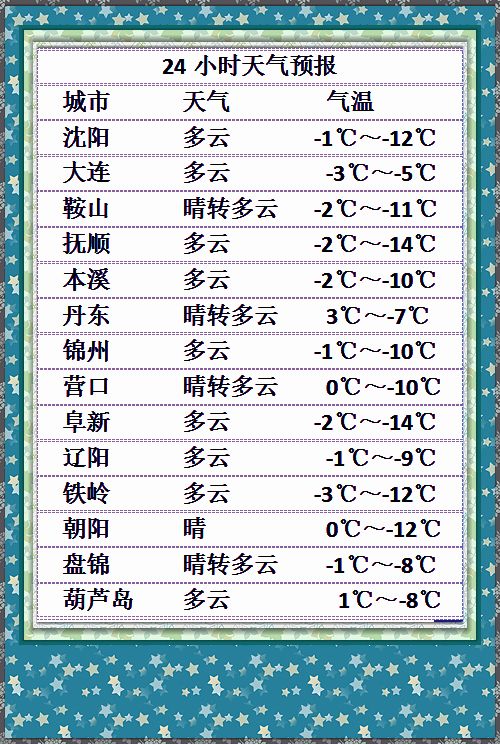
一笑一码 的理念也鼓励我们将数据分析的结果以直观易懂的方式呈现给非技术人员,利用可视化工具如Tableau、Power BI等,可以帮助决策者更好地理解数据背后的故事,从而做出更加明智的选择。
一笑一码 不仅仅是一种工作态度,更是一种追求卓越的精神,在数据分析的每一个环节中贯彻这一理念,将有助于我们不断提升分析的准确度,为企业创造更大的价值,达到100%的准确度是一个理想状态,现实中往往难以完全实现,通过不断的努力和创新,我们可以朝着这个目标稳步前进。
转载请注明来自有只长颈鹿官网,本文标题:《一笑一码100%准确,综合解答解释落实_5s266.13.92》





 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号