

468888凤凰天机图解十八,实时解答解释落实_9v95.00.80
在当今信息爆炸的时代,数据成为了决策的重要依据,无论是商业分析、科学研究还是政策制定,数据分析都扮演着至关重要的角色,作为一名资深数据分析师,我深知数据背后蕴含的巨大价值以及如何通过科学的方法和工具来解读这些数据,从而为企业和组织提供有价值的洞见和策略建议,本文将结合我的个人经验,探讨数据分析的关键步骤、常用工具与技术,并通过一个实际案例——“468888凤凰天机图解十八”的解析,展示如何将理论知识应用于实践,实现数据驱动的决策过程。
一、数据分析的关键步骤数据分析是一个系统化的过程,通常包括以下几个关键步骤:
1、需求明确:需要清晰地定义分析目标和业务问题,了解项目的背景、目的及预期成果是整个数据分析流程的基础。
2、数据收集:根据分析目标确定所需的数据类型和来源,进行数据收集,这可能涉及数据库查询、API接口调用、问卷调查、公开数据集等多种方式。
3、数据预处理:原始数据往往包含噪音、缺失值或不一致格式,需要进行清洗、转换和整合,以确保数据的质量和一致性,常见的预处理操作包括数据清洗、数据转换、特征工程等。
4、探索性数据分析(EDA):通过统计图表、摘要统计量来初步了解数据的分布、关联性等特征,为后续建模提供指导。
5、建模与算法选择:基于业务理解和数据特性选择合适的建模方法和算法,如回归分析、分类、聚类、时间序列分析等。

6、模型训练与评估:使用训练集数据训练模型,并利用验证集或测试集评估模型性能,常用的评估指标有准确率、召回率、F1分数、AUC值等。
7、结果解释与可视化:将模型输出转化为易于理解的形式,如图表、报告,并向非技术利益相关者清晰解释发现和建议。
8、部署与监控:将模型集成到生产环境中,持续监控其表现,并根据反馈进行迭代优化。
二、常用工具与技术编程语言:Python和R是数据科学领域最流行的编程语言,它们拥有丰富的库支持,如Python中的Pandas、NumPy、Scikit-learn、TensorFlow,R中的ggplot2、dplyr、caret等。
数据处理与分析平台:如Apache Spark、Hadoop用于处理大规模数据集;Tableau、Power BI用于数据可视化;Jupyter Notebook则是一个交互式的开发环境,便于数据分析和可视化。
数据库:关系型数据库(如MySQL、PostgreSQL)和非关系型数据库(如MongoDB、Cassandra)用于存储和管理数据。
三、案例分析:“468888凤凰天机图解十八”
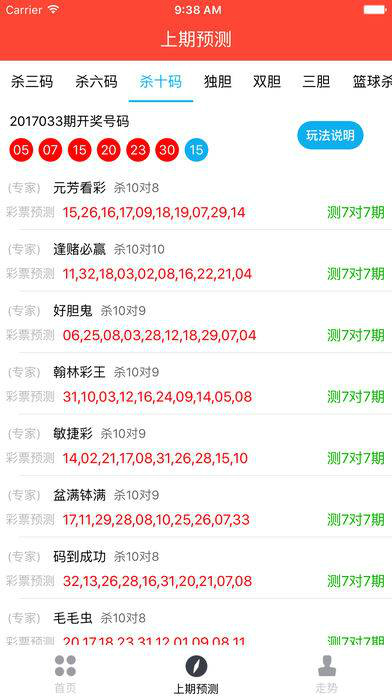
假设“468888凤凰天机图解十八”是一个特定的数据集或项目代号,涉及到一系列复杂数据的解析和预测任务,以下是一个简化的分析框架示例:
1、理解背景:我们需要深入了解“468888凤凰天机图解十八”背后的业务场景和具体问题,比如它是关于金融市场预测、用户行为分析还是其他领域的特定问题。
2、数据收集:根据问题定义,从相关数据库、API或文件中收集必要的数据,可能包括历史交易数据、用户日志、市场新闻等多源数据。
3、数据预处理:对收集到的数据进行清洗,处理缺失值、异常值,转换数据格式,构建适合分析的数据集,标准化数值特征,编码类别变量等。
4、探索性数据分析:通过绘制时间序列图、分布图、热力图等,探索数据的基本趋势、周期性、相关性等特征,识别潜在的模式和异常。
5、特征工程:基于EDA的结果,构造新的特征或选择最重要的特征,以提高模型的解释力和预测能力,从日期时间数据中提取出年份、月份、工作日等特征。
6、模型选择与训练:假设我们的目标是进行某种形式的预测,我们可能会尝试多种模型,如线性回归、随机森林、梯度提升树或神经网络等,通过交叉验证选择最佳模型。
7、结果解释与可视化:以直观的图表展示模型预测结果,比如使用折线图对比实际值与预测值,用条形图展示不同类别的预测概率等,同时编写详细的分析报告解释模型发现。
8、部署与反馈循环:将模型部署到生产环境,监控其在实际数据上的表现,定期回顾和调整模型以适应数据分布的变化。
数据分析是一项复杂但极具价值的活动,它要求分析师具备跨学科的知识、敏锐的业务洞察力以及扎实的技术功底,通过遵循科学的分析流程,运用合适的工具和技术,我们可以从海量数据中提炼出有价值的信息,为企业决策提供强有力的支持。“468888凤凰天机图解十八”的案例只是众多数据分析项目中的一个缩影,每个项目都有其独特性,但核心原则和方法是一致的,作为数据分析师,我们的使命就是不断探索数据背后的真相,助力组织做出更加明智的决策。
转载请注明来自有只长颈鹿官网,本文标题:《468888凤凰天机图解十八,实时解答解释落实_9v95.00.80》







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号